The Stanford School of Earth, Energy & Environmental Sciences is now part of the Stanford Doerr School of Sustainability.
This page is currently being maintained for archival purposes only. For the latest information, please visit us here.

Accurate information on the location of impoverished zones is surprisingly lacking for much of the world. Applying machine learning to satellite images could identify regions of poverty in Africa.
One of the biggest challenges in providing relief to people living in poverty is locating them. The availability of accurate and reliable information on the location of impoverished zones is surprisingly lacking for much of the world, particularly on the African continent. Aid groups and other international organizations often fill in the gaps with door-to-door surveys, but these can be expensive and time-consuming to conduct.
In the current issue of Science, Stanford researchers propose an accurate way to identify poverty in areas previously void of valuable survey information. The researchers used machine learning – the science of designing computer algorithms that learn from data – to extract information about poverty from high-resolution satellite imagery. In this case, the researchers built on earlier machine learning methods to find impoverished areas across five African countries.
"We have a limited number of surveys conducted in scattered villages across the African continent, but otherwise we have very little local-level information on poverty,” said study co-author Marshall Burke, an assistant professor of Earth system science at Stanford and a fellow at the Center on Food Security and the Environment. “At the same time, we collect all sorts of other data in these areas – like satellite imagery – constantly."
The researchers sought to understand whether high-resolution satellite imagery – an unconventional but readily available data source – could inform estimates of where impoverished people live. The difficulty was that while standard machine learning approaches work best when they can access vast amounts of data, in this case there was little data on poverty to start with.
"There are few places in the world where we can tell the computer with certainty whether the people living there are rich or poor,” said study lead author Neal Jean, a doctoral student in computer science at Stanford’s School of Engineering. “This makes it hard to extract useful information from the huge amount of daytime satellite imagery that’s available."
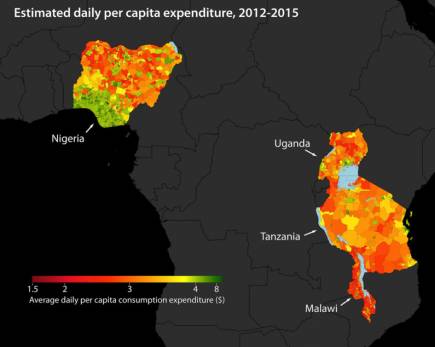
Because areas that are brighter at night are usually more developed, the solution involved combining high-resolution daytime imagery with images of Earth at night. The researchers used the “nightlight” data to identify features in the higher-resolution daytime imagery that are correlated with economic development.
"Without being told what to look for, our machine learning algorithm learned to pick out of the imagery many things that are easily recognizable to humans – things like roads, urban areas and farmland," said Jean. The researchers then used these features from the daytime imagery to predict village-level wealth, as measured in the available survey data.
They found that this method did a surprisingly good job predicting the distribution of poverty, outperforming existing approaches. These improved poverty maps could help aid organizations and policymakers distribute funds more efficiently and enact and evaluate policies more effectively.
"Our paper demonstrates the power of machine learning in this context,” said study co-author Stefano Ermon, assistant professor of computer science and a fellow by courtesy at Stanford Woods Institute for the Environment. "And since it’s cheap and scalable – requiring only satellite images – it could be used to map poverty around the world in a very low-cost way."
Co-authors of the study, titled "Combining satellite imagery and machine learning to predict poverty", include Michael Xie from Stanford's Department of Computer Science and David Lobell and W. Matthew Davis from Stanford's School of Earth, Energy & Environmental Sciences and the Center on Food Security and the Environment. For more information, visit the research group's website at sustain.stanford.edu.

© Stanford University, Stanford, California 94305. Copyright Complaints




